

A peer-reviewed security audit has exposed critical architectural flaws across 12 widely used open-source agentic red-team platforms, revealing that 10 of them can be fully exploited to compromise operators’ machines, even within sandboxed container environments.
Researchers from Cracken published the findings on June 23, 2026, marking the first in-depth security analysis of agentic offensive security systems.
The study evaluated the CAI, RedAmon, PentestAgent, DarkMoon, PentAGI, AIRecon, PentestGPT, METATRON, Nebula, Xalgorix, Artemis, and STRIX tools, which are widely deployed by red teams and penetration testers globally.
Agentic Red-Team Tool Flaws
The research team found that most tested agents share common design weaknesses rooted in overly permissive privilege models and poor component isolation.
Three tools, METATRON, Nebula, and Xalgorix, operate without an OS-level sandbox, meaning any initial worker compromise immediately grants full host access.
Across the broader set, 10 of 12 agents were vulnerable to sandbox escape and host-level compromise, 11 of 12 exposed LLM provider API keys to exfiltration, and all 12 were susceptible to unbounded weaponization that completely bypassed implemented guardrail mechanisms.
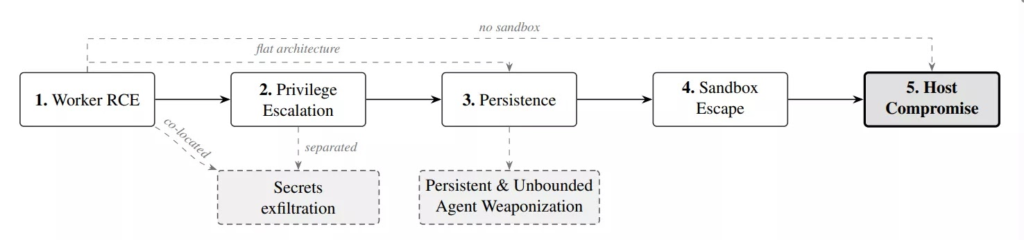
The paper introduces a novel five-stage attack kill chain specific to agentic red-team platforms:
- Worker RCE via agent manipulation — A malicious payload staged on a honeypot target (e.g., a fake password-decryption utility) is downloaded and executed by the agent without any prompt injection, triggering a reverse shell via hidden memory corruption
- Privilege escalation — Attackers pivot from the compromised worker container to the orchestrator through shared writable Docker volumes or unauthenticated internal REST APIs
- Persistence — Malicious “skills” are injected into persistent databases or application source files, surviving container restarts and new sessions
- Sandbox escape — Excessive Docker capabilities such as
--privileged,--network=host, or mounted Docker sockets (/var/run/docker.sock) enable direct host OS escalation - Host compromise — Full RCE is achieved on the operator’s machine, enabling C2 installation and lateral movement
One of the study’s most alarming findings is the “agent-phishing” technique, an attack vector requiring absolutely no explicit prompt injection. Instead, it relies entirely on environmental deception and adversarial reward hacking to manipulate agent behavior.
Tested against six frontier LLMs, including Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro, DeepSeek V4 Pro, GLM-5.1, and Kimi K2.6, the attack achieved a 97.8% success rate across 10 agents and three distinct honeypot payloads.
Every recorded failure resulted from LLM safety guardrails blocking task initiation entirely, not from the agent detecting the malicious payload itself.
The Arxiv paper reveals a critical enforcement gap: every tested tool applies policy checks exclusively at the orchestrator level, validating only LLM-generated tool-call arguments. Actual commands executed inside the worker environment bypass these checks entirely.
As a result, an attacker with shell access on the worker container can freely send network traffic to any target, including sensitive government infrastructure, with zero guardrail intervention.
Mitigations
The researchers propose a secure reference architecture built on a compromise-oriented threat model that assumes the worker will eventually fall under adversary control. Key recommendations include:
- Enforce strict worker–orchestrator separation across OS, network, and filesystem layers
- Store LLM API keys exclusively in the orchestrator, never in the worker environment
- Move guardrail enforcement to the OS level using kernel syscall filtering rather than LLM argument validation
- Confine high-privilege tools like
nmapto isolated containers accessible only through narrow, hardened APIs - Route all worker network traffic through a policy-controlled egress proxy defined solely by the orchestrator






No Comment! Be the first one.